Technisch ontwerp
- 1. Constraints
- 2. Principes
- 3. Software Architectuur
- 4. Front en backend components
- 5. Datastructuur
- 6. Deployment
- 7. Geautomatiseerde tests
- 8. Algemene technische keuzes
- Bronnen
Doel van dit document
Het technisch ontwerp is een document waarin de technische aspecten van het project worden beschreven. Hierin wordt onder andere de architectuur, externe interfaces, REST API endpoints, code structuur, data/database, deployment en technische keuzes beschreven. Sommige van deze hoofdstukken zijn terug te vinden in de onderliggende use cases.
1. Constraints
Het systeem waarin de uitbreidingen moeten komen bestaat al. In de bestaande applicaties wordt gebruik gemaakt van onder andere React, Typescript en C# .NET8 in combinatie met Entity Framework Core. Voor de database wordt gebruik gemaakt van MySQL. De nieuwe functionaliteit moet hierop aansluiten. Het bestaande systeem is gebouwd op basis van een veelgebruikte template van Bluenotion, deze template bevat al veel functionaliteit die in veel projecten vereist is. De nieuwe functionaliteit moet hierop aansluiten en de bestaande functionaliteit niet verstoren.
2. Principes
In dit project worden verschillende design patterns gehanteerd om de code zo toekomstbestendig en onderhoudbaar mogelijk te maken. In iedere use case wordt toegelicht welke design patterns worden toegepast en waarom deze worden toegepast. In het project wordt onder andere gebruik gemaakt van het (Strategy Pattern, n.d.) en het (Adapter Pattern, n.d.). Zie de volgende use cases voor meer informatie over de design patterns die worden toegepast:
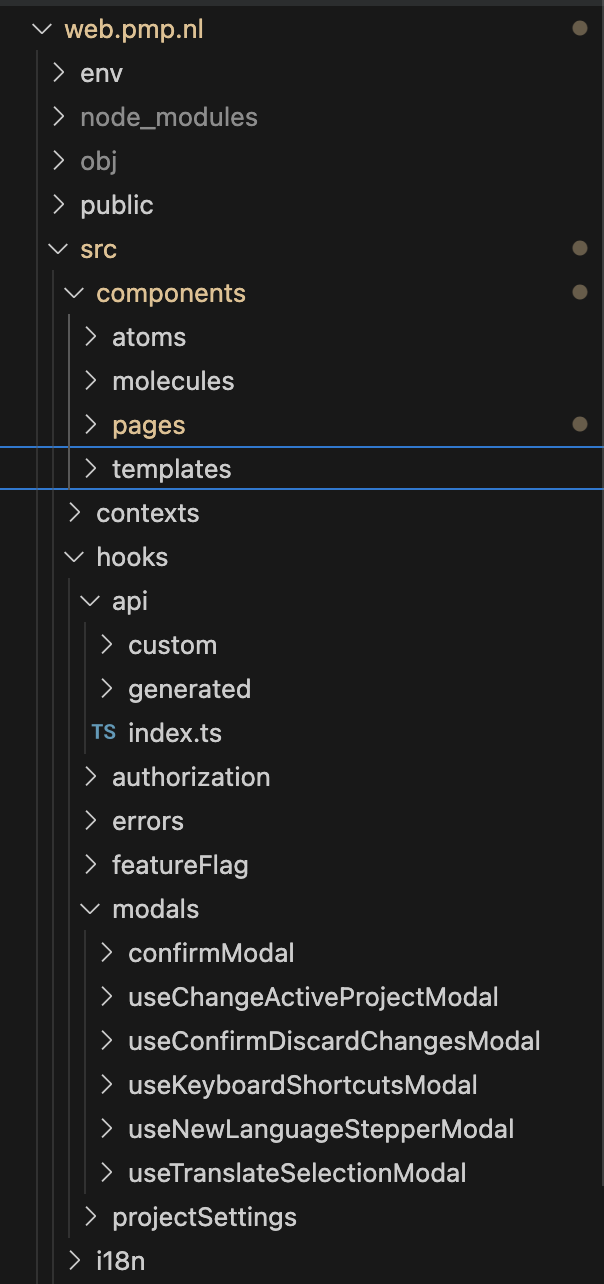
In de front-end wordt gebruik gemaakt van (Atomic Design | Atomic Design by Brad Frost, n.d.). In het volgende diagram is de folderstructuur van de front-end weergegeven, om een beeld van hoe het Atomic Design pattern toegepast wordt. Het atomic design pattern schrijft voor om 5 verschillende lagen toe te passen, in de front-end is 1 van de lagen weggelaten, namelijk organisms. Dit is gedaan omdat de front-end van de applicatie niet zo groot is dat er een aparte laag voor nodig is. De front-end is opgedeeld in de volgende lagen:
- Atoms: De kleinste bouwstenen van de applicatie, zoals buttons, inputs en labels.
- Molecules: Atoms die samen een grotere bouwsteen vormen, zoals een input met een label.
- Templates: De verschillende pagina layouts, zoals Admin en Gebruiker.
- Pages: De verschillende pagina's van de applicatie, zoals de login pagina en de home pagina.
Verder is ook te zien dat modals in de hooks folder terecht komen. Dit komt doordat er gebruikt gemaakt wordt van een package, die modals in een hook plaatst. Ook worden de endpoints van de API in de generated folder, binnen de hooks folder geplaatst. Deze hooks worden gegenereerd aan de hand van Bluenotion's script, die de endpoints van de C# .NET omzet naar typescript modellen en endpoints aanroep methoden. Bluenotion heeft ook een script voor vertalingen, voor beide de front- en back-end. De scripts worden gebruikt om de controleren of alle vertalingen aangemaakt zijn in pipelines, of als de ontwikkelaar dit script zelf uitvoert worden alle vertalingen bijgewerkt (aangemaakt of verwijderd).
De back-end gebruikt een 3 lagen architectuur, waarbij de lagen als volgt zijn opgedeeld:
- Controllers: De controllers zijn verantwoordelijk voor het ontvangen van de requests en het doorsturen van de requests naar de juiste service.
- Services: De services zijn verantwoordelijk voor de business logica van de applicatie. Hier worden de requests van de controllers verwerkt en wordt de data opgehaald en verwerkt.
- Repositories: De repositories zijn verantwoordelijk voor het ophalen en opslaan van data in de database.
Voor background jobs is een implementatie van Hangfire aanwezig, die ervoor zorgt dat de vertalingen op de CDN worden opgeslagen.
Tot slot gebruikt het project een pre-commit hook, die alle nieuwe code controleert op fouten volgens de gebruikte linters (zie hoofdstuk constraints hierboven). Ook worden alle tests gedraaid, en worden de vertalingen gecontroleerd. Als er een fout wordt gevonden zal de commit niet doorgaan en zal de ontwikkelaar de fouten moeten oplossen voordat de commit door kan gaan. Hetzelfde geldt voor de pipelines, echter controleren deze alle code en niet alleen de nieuwe code.
3. Software Architectuur
3.1. Systemen
In de volgende afbeelding zijn de verschillende systemen die betrokken zijn bij de applicatie en hoe deze communiceren weergegeven. Deze koppelingen zijn belangrijk voor de functionaliteit van de applicatie. En voor deze reden zijn deze koppelingen in kaart gebracht.

3.2. Containers
In de volgende afbeelding zijn de verschillende containers binnen het Klantportaal te zien. Deze containers brengen de verschillende onderdelen van de applicatie in kaart, en geven een goed beeld van welke container verantwoordelijk is voor welk onderdeel van de applicatie.

4. Front en backend components
Om de documentatie overzichtelijk te houden staan hier de front- en backend components per use case beschreven. Hieronder zijn de use cases te vinden waarin de front- en backend components beschreven worden.
-
UC1: Configureren project
-
UC2: Automatisch vertalen project
-
UC3: Vertalen woorden/teksten
5. Datastructuur
In het diagram van de datastructuur zijn alleen relevante tabellen opgenomen, in het diagram is te zien welke tabellen nieuw zijn, welke velden/tabellen zijn aangepast en welke tabellen al bestaan en niet aangepast zijn.

6. Deployment
In het volgende diagram is de deployment architectuur te zien. In dit diagram is te zien dat er 2 omgevingen zijn, namelijk de test omgeving en de productie omgeving. Deze draaien op losse servers bij dezelfde hosting provider (RootNet). Beide omgevingen hebben een eigen database, die op de bijbehorende server staat. In het diagram is een afsplitsing te zien op basis van de opgevraagde omgeving, de pijlen geven aan dat de API requests van de browser van de gebruiken doorgestuurd worden naar de bijbehorende hosting server, waar ze door de API Server afgehandeld worden. In de tegengestelde richting geldt dat de applicatie de inhoud van de pagina's ophaalt van de hosting server.

7. Geautomatiseerde tests
Voor alle tests wordt gebruik gemaakt van XUnit, een open-source unit test framework voor .NET. Voor de end-to-end tests wordt gebruik gemaakt van Playwright, een open-source tool om browser automatisering te testen. Verder wordt er gebruik gemaakt van Moq om mocks te maken voor de tests wanneer dit nodig is. Bij end-to-end tests wordt voor iedere class een aparte docker container met maria-db gemaakt om de tests te draaien. Verder zitten er een aantal handige helper functies in de standaard template van Bluenotion die uitgebreid zijn voor deze tests.
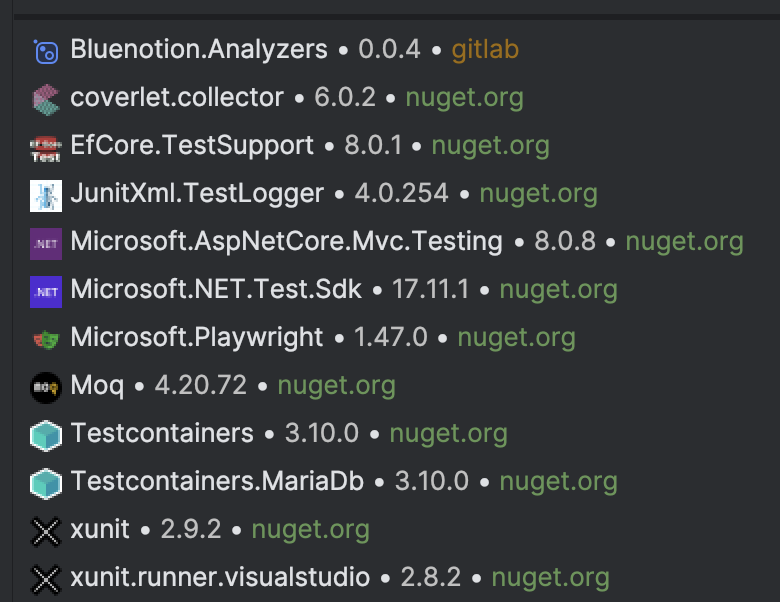
Zie de volgende afbeelding voor alle gebruikte nuget packages en versies:
Tests uitvoeren
Om alle tests in het project te draaien kan het volgende commando gebruikt worden:
Locatie
Zorg dat de volgende commando's uitgevoerd worden in de root van het back-end project
8. Algemene technische keuzes
8.1. OTA Update Service (CDN)
De applicatie heeft 2 opties als versiebeheer systeem, namelijk:
- GitLab
- Azure DevOps
Deze worden gebruikt om de vertalingsbestanden op te halen en op te slaan. In het git versiebeheer systeem komen de vertalingsbestanden eerst in een PR te staan. Om de nieuwe vertalingen in de vertalingsbestanden direct beschikbaar te maken voor de applicatie en zijn eindgebruikers is er besloten om een OTA Update Service te maken. Deze service zorgt ervoor dat de vertalingsbestanden direct beschikbaar zijn voor de applicatie en zijn eindgebruikers.
Op 7 November 2024 is na overleg met de opdrachtgever en andere collega's besloten om een CDN te gebruiken. Dit was niet de oplossing waar in eerste instantie aan gedacht werd, dat was namelijk een interne Nginx server in de server die de vertalingen beschikbaar zou maken. Zoals ook in de notities beschreven staat is er besloten om een CDN te gebruiken omdat: "Deze oplossing erg snel is en makkelijk gepubliceerd kan worden op meerdere plekken in de wereld, in tegenstelling tot een Nginx server".
Voor de CDN is er gekozen voor BunnyCDN. Deze CDN is gekozen omdat deze erg snel is en makkelijk gepubliceerd kan worden op meerdere plekken in de wereld. Verder is het opzetten erg makkelijk, is er een API beschikbaar en is de prijs relatief goedkoop.
De OTA Update Service werkt als volgt:
- De gebruiker genereert vertalingen voor een nieuwe taal, of past vertalingen aan voor een bestaande taal.
- De gebruiker slaat de aanpassingen op.
- De vertalingen worden opgeslagen in het git versiebeheersysteem, in een nieuwe branch waarvoor een PR wordt aangemaakt.
- De vertalingen worden opgeslagen op de CDN.
Wanneer de vertalingen zijn opgeslagen op de CDN, worden deze direct beschikbaar voor de applicatie en zijn eindgebruikers. De applicatie haalt de vertalingen op van de CDN en gebruikt deze om de vertalingen in de applicatie te tonen.
De back-end gebruikt een Hangfire job om nieuwe/aangepaste vertalingen op de CDN op te slaan.
De applicatie waarin de vertalingen beschikbaar moeten worden moet gebruik maken van i18next-chained-backend. Deze library zorgt ervoor dat de vertalingen van meerdere plekken opgehaald kunnen worden.
De front-end zoekt op 3 verschillende plekken naar vertalingen, op de aangegeven volgorde:
- In de local storage van de browser
- In de CDN als deze is geconfigureerd
- In de vertalingsbestanden die in de applicatie staan
De localStorage heeft een instelling waarmee cache ingesteld kan worden, als deze verlopen is zullen de vertalingen dus opnieuw opgehaald worden.
Als een ontwikkelaar vertalingen bijwerkt kan deze een nummer in het .env bestand aanpassen. Dit zal ervoor zorgen dat gebruikers die de applicatie open hebben staan de nieuwe vertalingen te zien krijgen wanneer ze opnieuw de applicatie openen.
Als de vertalingen die in de PR van het git versiebeheersysteem staan worden goedgekeurd en gemerged of als de branch of de merge request wordt verwijderd, zullen de vertalingen op de CDN worden verwijderd. Hierna zal ook de cache van de vertalingen in de CDN worden verwijderd, zodat de nieuwe vertalingen direct beschikbaar zijn voor de applicatie en zijn eindgebruikers.
Voor de gebruikers zal er in de applicatie een endpoint komen waarmee de localStorage cache geleegd kan worden. Als het ooit voor zou komen dat de gebruikers nieuwe vertalingen aan het vertalen zijn en deze niet direct zichtbaar zijn, kunnen ze de cache legen en zullen de nieuwe vertalingen direct zichtbaar zijn.
De OTA Update Service werkt alleen voor de front-end, de back-end biedt op dit moment geen mogelijkheid om vertalingen van meerdere plekken op te halen. Vandaar dat de back-end vertalingen alleen via het versiebeheersysteem bijgewerkt kunnen worden.
In het volgende diagram staat de flow van de OTA Update Service weergegeven:

8.2. Caching van vertalingen
De applicatie haalt per project vertalingen op van het versiebeheersysteem. Omdat het ophalen van de vertalingen van het versiebeheersysteem vaak gebeurt tijdens het vertalingsproces is er gekozen om de vertalingsbestanden te cachen voor een korte periode (15 minuten). Dit zorgt ervoor dat de vertalingsbestanden niet iedere keer opgehaald hoeven te worden van het versiebeheersysteem en de applicatie sneller laadt.
Ook worden alle vertalingsbestanden die omgezet zijn naar key value pairs gecached, omdat het ophalen van de inhoud van een bestand erg veel tijd kost. Deze cache geldt alleen voor de statistieken pagina. De cache staat ingesteld op 15 minuten. Maar het ophalen van de gegevens duurt gemiddeld 14-15 seconden, en dit wordt alleen maar langer op basis van hoe groot het project is. Dit is een erg lange tijd, en hier zal in de toekomst een oplossing op gevonden moeten worden.
Voor beide caches geldt dat als een gebruiker een vertaling aanpast of bewerkt, of een taal toevoegt dat de cache wordt geleegd. Dit zorgt dat de gebruiker geen oude vertalingen te zien krijgt.
Bronnen
- Strategy Pattern (n.d.). Geraadpleegd op 16 December 2024, van https://refactoring.guru/design-patterns/strategy
- Adapter Pattern (n.d.). Geraadpleegd op 16 December 2024, van https://refactoring.guru/design-patterns/adapter
- Atomic Design | Atomic Design by Brad Frost. (n.d.). Geraadpleegd op 16 December 2024, van https://atomicdesign.bradfrost.com/table-of-contents